VLPAR provides the automated deployment of multiple systems, depending upon the service level agreement(SLA) selected by the user when building a business solution. Those SLA's are described and depicted below.
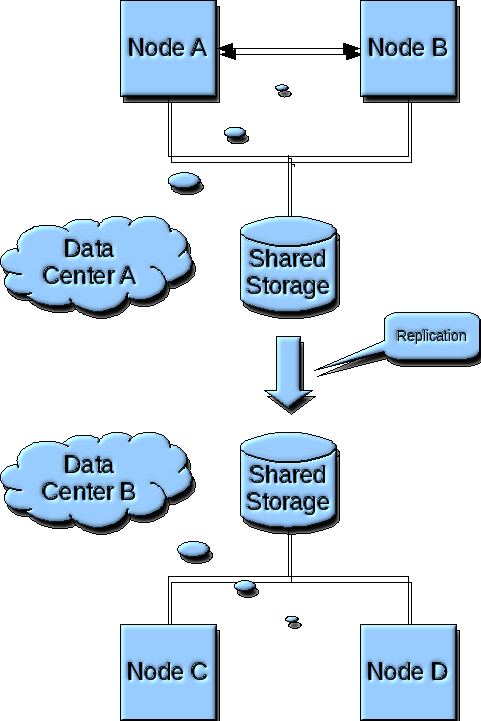
The following diagram depicts the Disaster Recovery and High Availability scenario for a Tier 1 service agreement level, as implemented by VLPARtm automated deployment. Under this scenario, four(4) nodes are created across two datacenters, two nodes in each datacenter.
In this scenario, both datacenters are considered to be running production business functions. These functions normally run on a single node in one of the datacenters, with a hot-standby node providing high availability fail-over capabilities. Periodically, for maintenance and disaster recovery testing, the business function load is shifted from one datacenter to the other. Once the business functions are running in the other datacenter, it is not failed-back until the next scheduled maintenance or an unscheduled outage to the datacenter occurs.
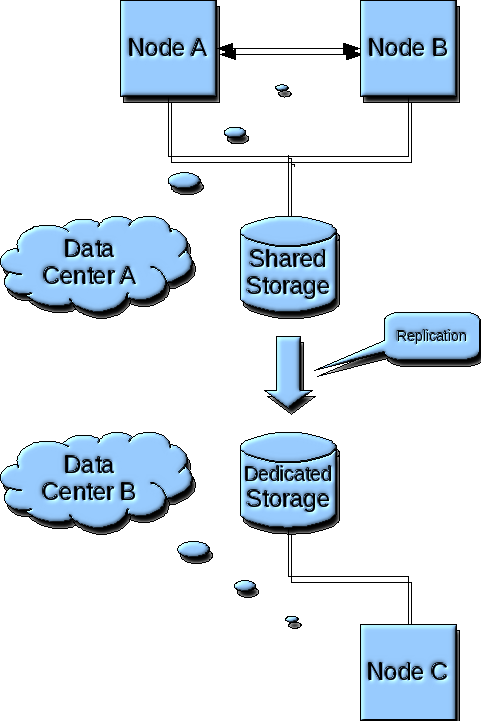
The following diagram depicts the Disaster Recovery and High Availability scenario for a Tier 2 service agreement level, as implemented by VLPARtm automated deployment. Under this scenario, three(3) nodes are created across two datacenters, two nodes in the primary production datacenter, one node in the disaster recovery datacenter.
In this scenario, the business functions are normally is normally running on a single node in the production datacenter. In the event of a hardware failure, the business functions are failed-over to a hot-standby node in the production datacenter. In the event of a datacenter failure, the business functions are failed-over to a hot-standby node in the disaster recovery datacenter.
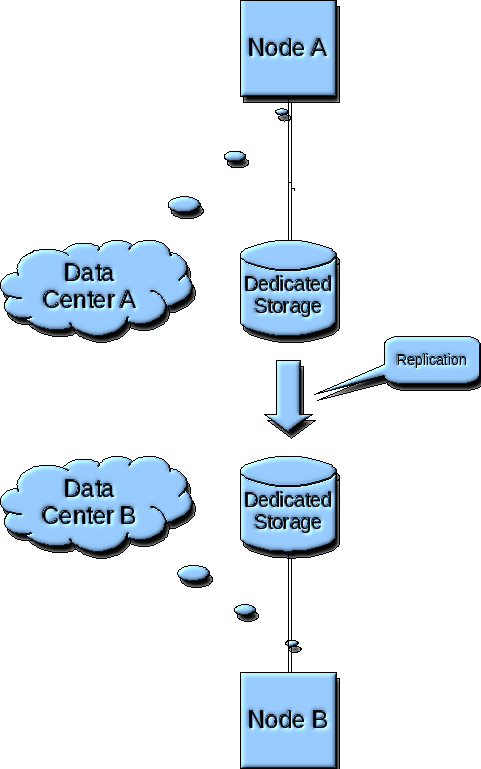
The following diagram depicts the Disaster Recovery scenario for a Tier 3 service agreement level, as implemented by VLPARtm automated deployment. Under this scenario, two(2) nodes are created across two datacenters, one node in each datacenter.
In this scenario, the business functions are running on running on a single node in the production datacenter. No high availability failover is provided, so in the event of a hardware failure on the production node, management must declare a disaster in order for a disaster recovery failover to be initiated. When a disaster is declared, the business functions are restarted on the disaster recovery node.
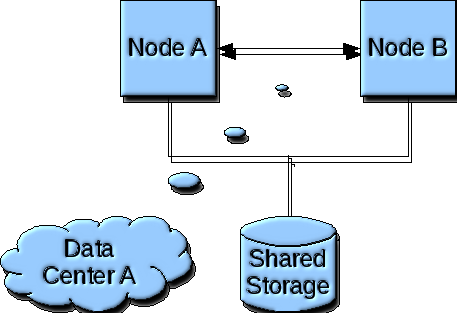
The following diagram depicts the Disaster Recovery and High Availability scenario for a Tier 4 service agreement level(SLA), as implemented by VLPARtm automated deployment. Under this scenario, two(2) nodes are created in an HACMP cluster within a single datacenter.
In this scenario, a two(2) node one-way cascading HACMP cluster is running in the production datacenter. The business functions normally run on a single node in the cluster, with a hot-standby node providing high availability fail-over capabilities. In the event of a hardware failure, the business functions are failed-over to the hot-standby node. In the event of a disaster, no pre-built provisions exist.
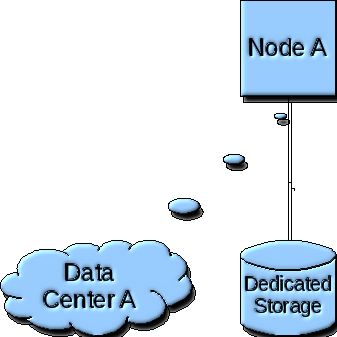
The following diagram depicts the Disaster Recovery and High Availability scenario for a Tier 5 service agreement level(SLA), as implemented by VLPARtm automated deployment. Under this scenario, one(1) node is created as a standalone systems within a single datacenter.
In this scenario, a single standalone system exists running the business functions, no high availability fail-over or disaster recovery fail-over provisions exist. If a hardware failure occurs, the business functions provided by the node will be unavailable until the failure is corrected.